2. Updating Data
In the previous article I showed how to fetch data from yfinance and store it as parquet. In this article, I will show how to keep the data updated. We'll be using the python package from finnhub.io (finnhub-python) instead of yfinance. Finnhub.io has a free tier which is rate limited to 60 request/minute. I will show how we can keep from exceeding this cap.
First, the imports:
import polars as pl
import arrow
import finnhub
from limit import limitLet's create a variable for where we are storing the data and set up the api key for finnhub.
data_directory = "./data/daily"
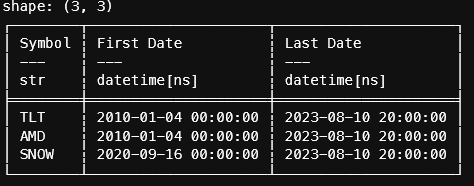
finnhub_api_key = "................"Next, we need to know what the most recent date is for our data set. Polars makes this easy.
df = (pl.scan_parquet(f"{data_directory}/*.parquet")
.groupby("Symbol")
.agg(
pl.col("Date").min().alias("First Date"),
pl.col("Date").max().alias("Last Date")
)
.collect()
)
Instead of re-fetching all the data points, we'll just get everything since the last update.
Let's create a function to retrieve the data from finnhub.io. The limit package has a nice decorator for throttling the requests. In the function below, we limit the number of calls to fetch_finnhub() to 60 requests every 60 seconds.
@limit(60,60)
def fetch_finnhub(symbol:str, starttime:arrow, endtime:arrow, finnhub_api_key:str, interval:str='D') -> dict:
finnhub_client = finnhub.Client(api_key=finnhub_api_key)
content = finnhub_client.stock_candles(
symbol,
interval,
int(starttime.datetime.timestamp()),
int(endtime.datetime.timestamp())
)
if 'no_data' in content.values():
return None
return contentFinnhub returns stock data in a very concise dictionary so we'll have to convert this to a dataframe. The function looks long but polars' expression syntax makes it very easy to understand.
def convert_finnhub_to_polars(symbol:str, content:dict)-> pl.DataFrame:
df = (pl.from_dict(content)
.with_columns([
# finnhub timestamps are in unix time (seconds) in GMT so
# we have to replace the timezone, convert to ET and then
# remove the timezone
pl.from_epoch("t")
.dt.replace_time_zone("GMT")
.dt.convert_time_zone("US/Eastern")
.dt.replace_time_zone(None)
def convert_finnhub_to_polars(symbol:str, content:dict)-> pl.DataFrame:
df = (pl.from_dict(content)
.with_columns([
# finnhub timestamps are in unix time (seconds) in GMT so
# we have to replace the timezone, convert to ET and then remove it
pl.from_epoch("t")
.dt.replace_time_zone("GMT")
.dt.convert_time_zone("US/Eastern")
.dt.replace_time_zone(None)
# we'll have to change this to use pl.Date type
.cast(pl.Date)
.alias("Date"),
# add the symbol as a column for easier grouping
pl.lit(symbol).alias("Symbol"),
# cast the types to ensure all of the data is homogenous and change the names
pl.col("v").cast(pl.Int64).alias("Volume"),
pl.col("c").cast(pl.Float64).alias("Close"),
# finnhub doen not have an adjusted close like yahoo so we'll
# have to substitute it with the close
pl.col("c").cast(pl.Float64).alias("Adj Close"),
pl.col("h").cast(pl.Float64).alias("High"),
pl.col("l").cast(pl.Float64).alias("Low"),
pl.col("o").cast(pl.Float64).alias("Open"),
])
.select([
pl.col('Date'),
pl.col('Open'),
pl.col('High'),
pl.col('Low'),
pl.col('Close'),
pl.col('Adj Close'),
pl.col('Volume'),
pl.col('Symbol')
])
)
return df
.cast(pl.Date)
.alias("Date"),
# add the symbol as a column for easier grouping
pl.lit(symbol).alias("Symbol"),
# cast the types to ensure all of the data is homogenous
# and change the names
pl.col("v").cast(pl.Int64).alias("Volume"),
pl.col("c").cast(pl.Float64).alias("Close"),
# finnhub doen not have an adjusted close like yahoo so we'll
# have to substitute it with the close
pl.col("c").cast(pl.Float64).alias("Adj Close"),
pl.col("h").cast(pl.Float64).alias("High"),
pl.col("l").cast(pl.Float64).alias("Low"),
pl.col("o").cast(pl.Float64).alias("Open"),
])
.select([
pl.col('Date'),
pl.col('Open'),
pl.col('High'),
pl.col('Low'),
pl.col('Close'),
pl.col('Adj Close'),
pl.col('Volume'),
pl.col('Symbol')
])
)
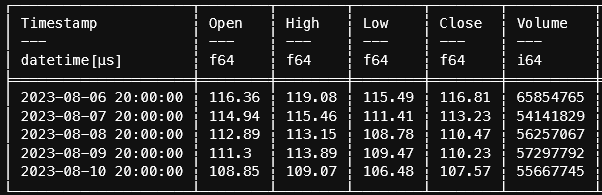
return dfFinnhub returns:
{'c': [116.81, 113.23, 110.47, 110.23, 107.57], 'h': [119.08, 115.46, 113.15, 113.89, 109.07], 'l': [115.49, 111.41, 108.78, 109.47, 106.48], 'o': [116.36, 114.94, 112.89, 111.3, 108.85], 's': 'ok', 't': [1691366400, 1691452800, 1691539200, 1691625600, 1691712000], 'v': [65854765, 54141829, 56257067, 57297792, 55667745]}Polars conversion:
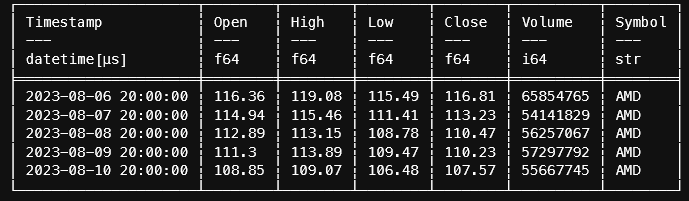
Finally, we need to update the most recent data with historicals. Again, polars makes this easy.
def merge_and_save(df:pl.DataFrame, filename:str) -> None:
'''
Merge the dataframe with the historicals.
'''
(pl
.read_parquet(filename)
# use vstack to append the latest data
.vstack(df)
# if there happens to be an overlap with the data, use the
# unique function and keep the most recent
.unique(subset='Date', keep='last')
# write everthing out
.write_parquet(filename)
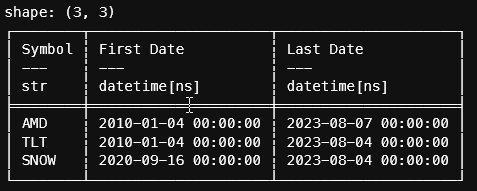
)Let's put it all together in a loop.
# using the data from for what we currently have on disk
for item in df.iter_rows(named=True):
# get the symbol since we'll need that for the finnhum request
symbol = item.get("Symbol")
# get the last date of the data
last_date = arrow.get(item.get("Last Date"))
# fetch the raw content from finnhub. Notice that we use the now()
# function from arrow to get today's date.
data = fetch_finnhub(symbol, last_date, arrow.now(), finnhub_api_key)
# convert the response to a polars dataframe
df_convert = convert_finnhub_to_polars(symbol, data)
# merge and save the data
merge_and_save(df_convert, f"{data_directory}/{symbol}.parquet")Take another look at the most recent dates from the first polars recipe: